
In the third part of this blog series, we will explain:
- How you can import data from Amazon Kinesis Data Streams with our Loading...analytics database
- How this can give you a performance boost when you need insights from real-time data
What is Amazon Kinesis Data Streams?
Kinesis Data Streams (KDS) is a real-time data streaming service provided by Amazon. It lets you continuously collect and temporarily store data from multiple sources. You can create custom applications that process or analyze streaming data. The architecture of KDS is very similar to Apache Kafka.
Before we start, here are the KDS terms we’re going to be using for each step:
- Data record – a single data unit
- Shard – a unique component of KDS consisting of multiple data records. One Stream can contain one or more shards
- Producer – an application that puts data records into shards
- Consumer – an application that gets data records from shards
How does it work?
You create a Kinesis Stream specifying the number of shards in the stream.
The more shards a stream has the more data capacity it has. When the stream is ready, it can start collecting data from producers and giving it to consumers. The user can create custom producers and consumers or use ready-to-use services provided by Amazon or third parties.
The data records that producers send to the Stream are stored for up to 24 hours by default, but the time can be extended. Consumers, in turn, get the data records from the Stream and process it.
How does Kinesis Data Streams integrate with our analytics database?
Exasol Kinesis Connector (EKC) is an open-source project officially supported by Exasol.
The connector provides user-defined functions (Loading...UDFs), allowing users to transfer data records from Kinesis Stream directly to an Exasol table. In other words, EKC is a consumer.
To start using EKC you need to:
1. Create a Kinesis Stream
2. Create one or more producers
Currently, EKC supports data records in a JSON format. For example, we have a producer that sends data from some sensors to a Kinesis Stream in a JSON format:
{“sensorId”: 17,”currentTemperature”: 147,”status”: “WARN”}.
Using EKC we can easily retrieve this data from the stream and save it into an Exasol table.
Deploying and running Exasol Kinesis Connector
Step #1 – creating a Kinesis stream
To deploy and use the connector you first have to create a Kinesis stream. You can check the AWS Kinesis Documentation if you have never worked with Streams.
For example, we created a stream named ‘Test stream’ with one shard.
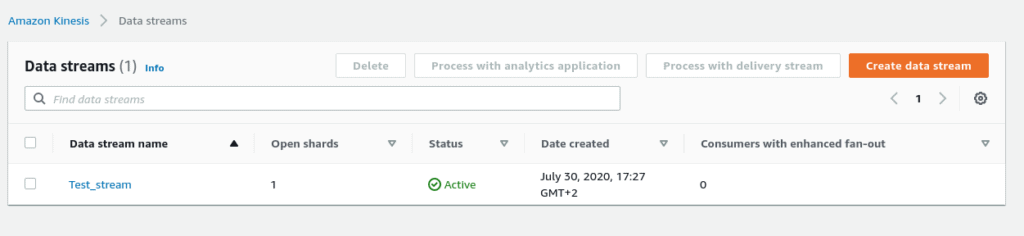
Step #2- setting up a producer
When the stream is ready, we set up a producer to put some data into the stream. We use the Amazon Kinesis Data Generator – a simple application with a graphical interface provided by Amazon for testing purposes.
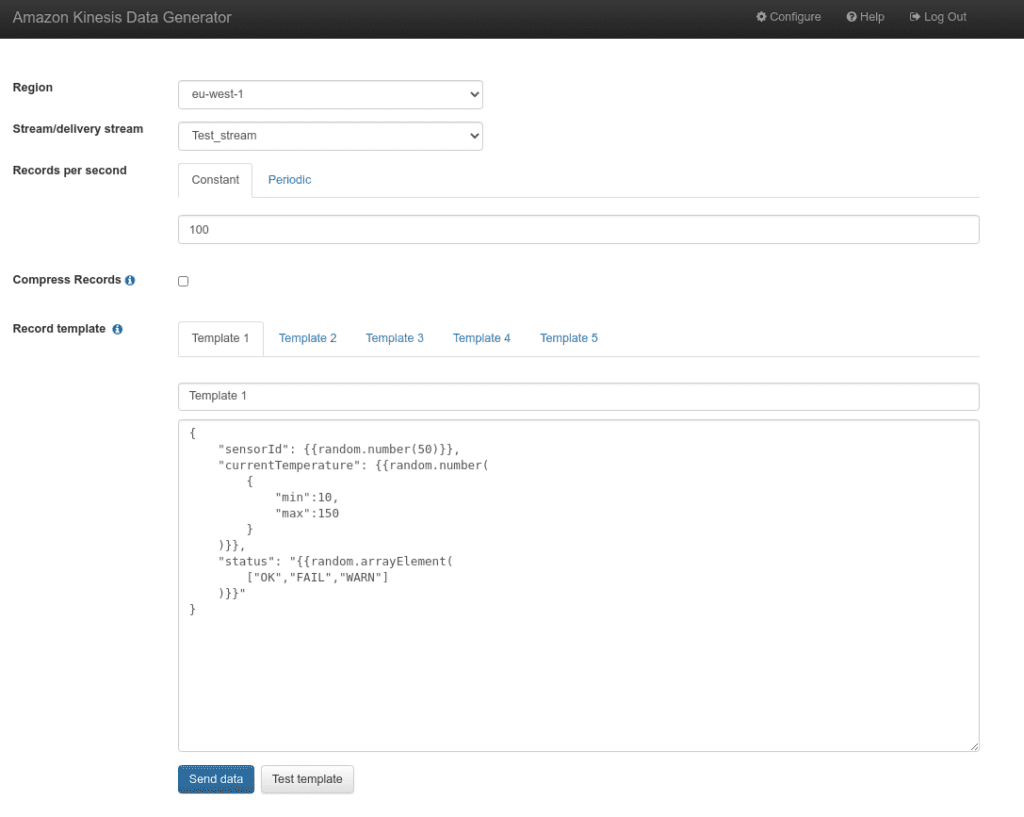
Step #3 – preparing the connector
To store data from a stream, we need a table. The columns in the table have to imitate the data types of the data stored in the stream and also be in the exact order.
The table also requires two additional columns to store the Kinesis metadata:
KINESIS_SHARD_ID VARCHAR(2000), SHARD_SEQUENCE_NUMBER VARCHAR(2000).
These two columns should be placed at the end of the table.
Let’s create a table for a JSON string I mentioned above:
{“sensorId”: 17,”currentTemperature”: 147,”status”: “WARN”}.
CREATE SCHEMA kinesis_schema;OPEN SCHEMA kinesis_schema;CREATE OR REPLACE TABLE kinesis_table(sensorId DECIMAL(18,0),currentTemperature DECIMAL(18,0),status VARCHAR(100),-- Required for importing data from Kinesiskinesis_shard_id VARCHAR(2000),shard_sequence_number VARCHAR(2000));We expect `sensorId` to be an integer. The column type can be changed to DECIMAL(5,0), for example, if we’re sure we only get small integers. The same applies for VARCHAR’s size – we can change the length of the VARCHAR if the expected strings are short. The last two columns are mandatory.
Step #5 creating UDFs
After the table is ready, we create UDFs:
CREATE OR REPLACE JAVA SET SCRIPT KINESIS_METADATA (...) EMITS (KINESIS_SHARD_ID VARCHAR(130), SHARD_SEQUENCE_NUMBER VARCHAR(2000)) AS%scriptclass com.exasol.cloudetl.kinesis.KinesisShardsMetadataReader;%jar /buckets/bfsdefault/kinesis/exasol-kinesis-connector-extension-<VERSION>.jar;/;CREATE OR REPLACE JAVA SET SCRIPT KINESIS_IMPORT (...) EMITS (...) AS%scriptclass com.exasol.cloudetl.kinesis.KinesisShardDataImporter;%jar /buckets/bfsdefault/kinesis/exasol-kinesis-connector-extension-<VERSION>.jar;/;CREATE OR REPLACE JAVA SET SCRIPT KINESIS_CONSUMER (...) EMITS (...) AS%scriptclass com.exasol.cloudetl.kinesis.KinesisImportQueryGenerator;%jar /buckets/bfsdefault/kinesis/exasol-kinesis-connector-extension-<VERSION>.jar;/;If you use DbVisualizer, place a comment mark(–/) before each CREATE command.
We also create an Exasol named connection object that contains AWS credentials. They’re added as key-value pairs separated by a semicolon (`;`). `AWS_SESSION_TOKEN` is an optional property. You can remove it from the string if you don’t need it:
CREATE OR REPLACE CONNECTION KINESIS_CONNECTIONTO ''USER ''IDENTIFIED BY 'AWS_ACCESS_KEY=<AWS_ACCESS_KEY>;AWS_SECRET_KEY=<AWS_SECRET_KEY>;AWS_SESSION_TOKEN=<AWS_SESSION_TOKEN>';Step #6 – running the connector
Finally, we’re ready to run the connector. The IMPORT command contains an additional property `MAX_RECORDS_PER_RUN`. That means we only want to import the first ten data records and stop there. The default limit is 10.000 data records, which is a limit of KDS :
IMPORT INTO kinesis_tableFROM SCRIPT KINESIS_CONSUMER WITHTABLE_NAME = 'kinesis_table'CONNECTION_NAME = 'KINESIS_CONNECTION'STREAM_NAME = 'Test_stream'REGION = 'eu-west-1'MAX_RECORDS_PER_RUN = '10';And to help you, here’s a quick explanation of the parameters for the IMPORT command:
TABLE_NAME – the name of the Exasol table to import to
CONNECTION_NAME – the name of the Exasol named connection
STREAM_NAME – the name of the stream we want to import from
REGION – the name of the AWS region the specified stream bound to
MAX_RECORDS_PER_RUN – how many records we want to import in a single run of the IMPORT command
If we query the Exasol table, you can see 10 data records imported from the stream. The import is done. We can run the IMPORT command again and again – and save new records to the table.
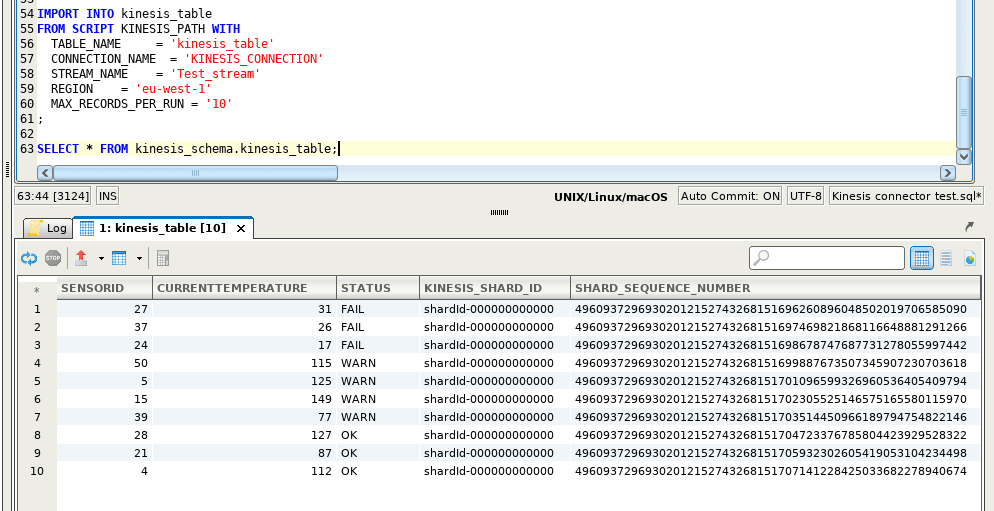
You can also check the user guide on the GitHub for additional details.
Q&A – everything you need to know about EXASOL Kinesis Connector
Here are answers to the most common questions about the connector.
What kind of data can you import using the connector?
Currently, when you input data the connector only supports it in a JSON format . You can check the user guide to know more about it.
How can you set up data transfer between a stream and an Exasol table?
We use the IMPORT INTO … FROM SCRIPT … command to transfer data from external data sources into our analytics database. The IMPORT command uses UDFs to get and prepare data and writes the data into an Exasol table in a single transaction.
Why do you need to create three UDFs to use the connector?
Because each UDF has different responsibilities and emits (returns) different values. So, we can’t collect the data from the stream before we read the metadata. Likewise, we can’t get the metadata for the table from inside the connector itself. That’s why we need to create the following three UDFs:
KINESIS_METADATA collects metadata about our table and the latest processed data records if some exist.
KINESIS_IMPORT connects to a stream and gets data records from KINESIS_METADATA. It also transforms the data is receives – and emits it in a format that works with an Exasol table.
KINESIS_PATH connects the two mentioned UDFs and emits the real data together with metadata. The IMPORT command directly uses the data emitted by KINESIS_CONSUMER.
Why do you need to create additional columns for the metadata – and can’t it be stored somewhere else?
The columns for metadata are a mandatory requirement if you want to use the connector. In a table with imported data, it can look like this:

The metadata is written for each data record and contains two important elements:
- a shard’s ID, showing where the record was retrieved
- A unique sequence number in a shard.
Without this metadata, you can’t pick up from where you last were and start consuming. You also can’t store this metadata in a separate table because a single import command can’t write data to two different tables.
But you can reduce the amount of stored metadata by saving only the latest imported sequence number instead of saving all of them. We are considering this as a future feature.
Can some data be duplicated or lost when I use the connector?
If a stream itself doesn’t contain duplicated data, it won’t be duplicated in an Exasol table. If an error happens during a transaction, we won’t commit the changes. The IMPORT process will start again with the next command run – continuing from the position of the last successful import.
The data also can’t be lost during the transferring process, but it can be removed from a stream itself before you transferred it to an Exasol table. For example, if you don’t run the IMPORT command for more than 24 hours, you can miss some data because it’s stored for only 24 hours in a stream, by default.
Why can’t I leave the connector to run constantly, but have to re-run the IMPORT command again and again?
We currently can’t run a daemon thread which can repeatedly insert the data inside the database. The IMPORT command can only insert data with a commit of a transaction. That means that it needs to stop at some point to save the data. After the data is saved, we can start another import.
Can I automate the IMPORT command?
Yes, you can. You can schedule an Exaplus command to run via a cronjob. It would run the IMPORT command. Check how to do it on our blog post.
Got any more questions? Post it in comments on our Community portal – or create a GitHub ticket. Your feedback is always appreciated.