Blog snapshot:
This post will show you:
- The three key components of Apache Kafka architecture
- How to integrate Apache Kafka and Exasol using Kafka Connect JDBC Connector
What is Kafka?
Apache Kafka is a distributed streaming platform that is horizontally scalable, fault-tolerant, fast and runs in production in thousands of companies.
It has stood the test of the time. The most common usage of Kafka as the central data platform that allows you to reliably provide data between systems or applications.
So, how does it work?
Apache Kafka Architecture
In this section, I am going to provide a brief introduction to the Apache Kafka architecture. I will mainly concentrate on three parts: topic, brokers and consumers. These three components will be relevant later on as they will affect how we design the Exasol and Kafka connector.
Kafka Topic
Apache Kafka topic is an abstraction that represents distribution of data over several partitions. Kafka stores each data record in the order of their arrival inside a partition. Additionally, Kafka assigns a sequence number to each record in ascending order, called offset of the partition.
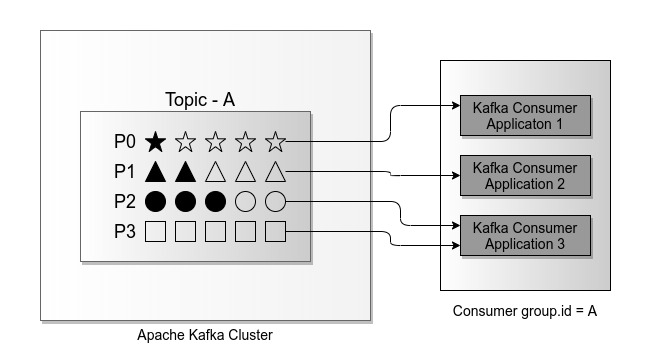
Conceptually, users or applications consume data from one or more partitions of a Kafka topic. These consumers are assumed to be unreliable, that they can fail, stop or disconnect at any time. Usually, a set of consumers are abstracted into a group. This helps when there are many different interested departments or microservices for the data inside a particular topic.
bin/kafka-topics \ --zookeeper z0.domain.com:2181,z1.domain.com:2181,z2.domain.com:2182 \ --create \ --partitions 4 \ --replication-factor 3 \ --config max.message.bytes=1073741824 \ --topic topicAIn the above short snippet, you can see that we have created a topic, named as topicA, that has four partitions. We also set the replication factor and topic specific configuration parameters. Please refer to the Kafka documentation to learn more about these settings.
One thing you should notice is that we do not define any topic schema, column names or types, when creating a topic. In a typical Kafka installation there is also a Schema Registry service that registers and maintains a topic schema.
Kafka Brokers
The Kafka Brokers are the physical servers in the Kafka cluster. They store and maintain the topic partitions.
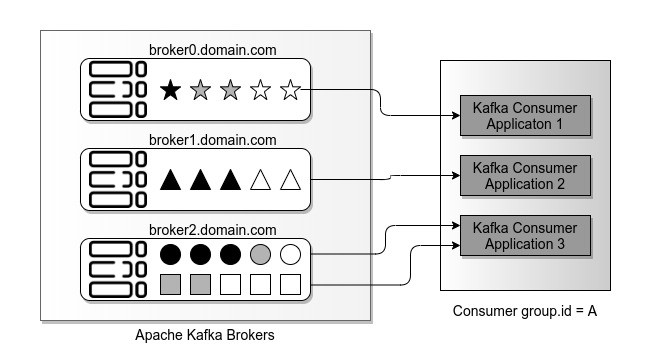
In the above setup, the three brokers are responsible, usually called leaders, of the four topic partitions.
In the previous section, I mentioned that a topic can have a replication factor. This applies to the partitions. They can be replicated to other brokers in addition to the leader broker. This can help to improve the latency — but on the other hand it increases the storage size of the Kafka cluster.
Managing the state of the records
Another important concept is the state of each record inside the partitions. Record state is “new” for example, when a producer delivered a new record. “Consumed” means a consumer has read or requested that record. Last but not least “committed” says, that the consumption of a record has been finished and reported to a broker. Brokers will not send any committed records to the applications in a particular consumer group.
How do brokers manage these states?
There are three main approaches for managing the record states:
- A Kafka cluster periodically commits the records after sending them to consumers.
- Consumer applications ask the Kafka cluster to commit records inside a partition up to a specific offset.
- Consumers themselves manage the record offsets. Thus, they know from which offset to start consuming records inside a partition when they start the next time.
In the picture above, all the white shapes represent new records that consumer applications can request and consume. The dark black shapes are the data records that one of the consumers committed. Kafka brokers will not send these again to any consumer in a consumer group. The gray shapes represent data records that have been send to a consumer. Broker did not receive any acknowledgement if the record was successfully received and processed by a consumer.
These concepts will be useful later on when we design an Exasol User Defined Function (UDF) in order to import data from Kafka. However, let’s first see how to integrate Apache Kafka and Exasol using Kafka Connect JDBC Connector.
How to use Kafka Connect JDBC with Exasol
One solution to transfer data between Apache Kafka and Exasol is to use Kafka Connect JDBC Connector. Kafka Connect is an additional framework for connecting Kafka with external systems such as databases, Loading...key-value stores, search indexes and file systems. It comes with many connectors to import and export data from some of the most commonly used data systems. Kafka Connect Connectors provide both import and export capabilities. Additionally, they automatically manage partitioning, offset management, schema evolution and many other operations.
One of these connectors is Kafka Connect JDBC Connector. You can use this connector to transfer data between any Loading...relational database with a JDBC driver and Apache Kafka. We have an open-source kafka-connect-jdbc-exasol project that you can use together with Kafka Connect JDBC connector and Exasol JDBC Driver.
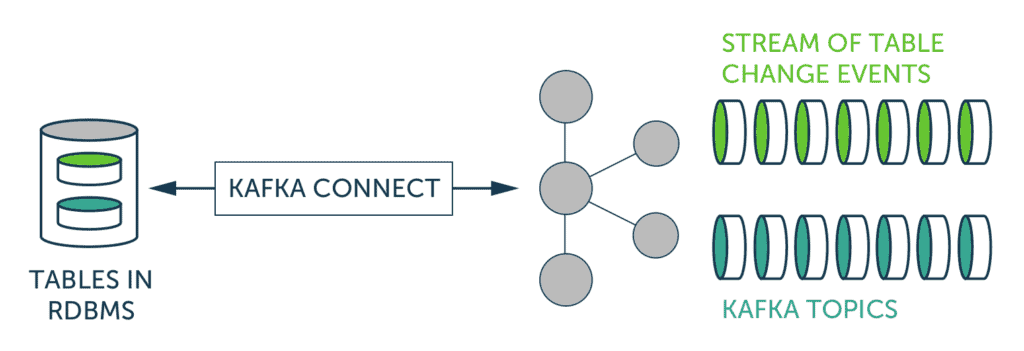
The JDBC Connector detects the new records in Kafka topic and sends them to Exasol database using prepared INSERT or MERGE statements. It will also detect the schema change in the Kafka topic, run appropriate ALTER TABLE commands to change the table column names and types.
Limitations
Apache Kafka is designed to be an always-on streaming solution. The Kafka Connect solution will keep the JDBC connection open by regularly contacting the Exasol database. Unfortunately, this is not ideal for the Exasol database since JDBC connections could increase the database overhead and make it less efficient.
Similarly, since we only provide an Exasol dialect code, it can be limiting when it comes to scaling, updating or improving the implementation.
What’s next?
In the next part of the blog we are going to see how to import data from Kafka using Exasol User Defined Functions (Loading...UDFs) which will provide a solution to the challenges mentioned above.